Sampling methods for surveys: Which is right for you?
Explore the most common probability and non-probability sampling methods, their trade-offs, and how to choose the right one for your survey.
.webp)
You can't survey everyone. Even with unlimited budget and infinite patience, reaching an entire population is rarely practical—and almost never necessary. What you can do is choose the right subset of people to represent the whole. That choice is your sampling method, and it shapes the accuracy, cost, and credibility of everything your survey produces.
The challenge is that "the right method" isn't universal. It depends on your research goals, your resources, and the population you're studying.
This guide breaks down the most widely used sampling methods, explains when each one shines, and helps you pick the one that fits your specific situation.
Probability vs. non-probability sampling
Every sampling method falls into one of two categories. Understanding the distinction is the first step in knowing which method is right for you.
Probability sampling means every member of the population has a known, non-zero chance of being selected. Selection is driven by randomization. The result is a sample you can statistically generalize to the full population, meaning you can calculate margins of error and confidence intervals.
Non-probability sampling means selection isn't random. Participants might be chosen based on convenience, judgment, or availability. The results can be insightful and useful, but you can't formally generalize them with the same statistical rigor.
Probability methods are the benchmark for academic research, policy studies, and any context where statistical generalizability matters. Non-probability methods are faster, cheaper, and often good enough for business decisions, product research, and exploratory work.
Probability sampling methods
These methods use randomization to reduce bias and produce results you can generalize with measurable confidence.
Simple random sampling
Every person in the population has an equal chance of being selected. You need a complete list of the population, then use a random mechanism (random number generator, lottery draw) to pick participants.
Best for: This method works well with populations that are relatively homogeneous and where you have a complete sampling frame (like a customer database or employee roster).
Drawback: If important subgroups are small, random chance might exclude them entirely. A 5% minority in your population might not show up at all in a sample of 100.
Stratified sampling
Divide the population into meaningful subgroups—strata—then randomly sample from each stratum in proportion to its size. If your customer base is 70% individual users and 30% enterprise accounts, your sample reflects that split.
Best for: This method works well with populations that have distinct subgroups you know matter for your research question. Stratification guarantees each group is represented, which improves precision without increasing sample size.
Drawback: You need to know the subgroup proportions in advance, and you need a way to classify people into strata before selection.

Systematic sampling
Select every nth person from a list. If your population has 10,000 people and you want a sample of 500, you'd select every 20th person (10,000 / 500 = 20). Start at a random point in the list and go from there.
Best for: This method suits large populations with an ordered list where random number generation is impractical. It's simpler to execute than simple random sampling and produces similar results in most cases.
Drawback: If the list has a hidden pattern that aligns with your selection interval, you'll get a biased sample. An employee roster sorted by department, sampled every 20th name, might overrepresent one department if department sizes happen to be multiples of 20.
Cluster sampling
Divide the population into clusters (usually geographic areas), randomly select some clusters, and survey everyone—or a random subset—within those clusters.
Best for: This method suits large, geographically dispersed populations where a full sampling frame doesn't exist. National surveys often use this approach, randomly selecting cities or regions first and then sampling within them.
Drawback: Higher sampling error than other probability methods, because people within clusters tend to be more similar to each other than to the population at large.
Multi-stage sampling
A combination approach that uses different methods at different stages. You might use cluster sampling to select regions, stratified sampling to select neighborhoods within those regions, and simple random sampling to select households within those neighborhoods.
Best for: This approach suits large-scale surveys where no single method is practical at every level. Government censuses, public health studies, and international research typically use multi-stage designs.
Drawback: Complex to design, execute, and analyze. Errors compound across stages, so each stage needs to be carefully planned.
Non-probability sampling methods
These methods don't rely on random selection. They're less rigorous statistically but faster, cheaper, and often the only realistic option.
Convenience sampling
Sample whoever is easiest to reach—your website visitors, your social media followers, the people walking past your booth at a conference. There's no attempt at randomization or representation.
Best for: This method works well for early-stage research, pilot testing, quick pulse checks, and situations where formal rigor isn't required. If you're testing whether a survey question makes sense before a full launch, convenience sampling is perfectly appropriate.
Drawback: Results may not represent anyone beyond the specific people you reached. Convenience samples tend to overrepresent people who are already engaged with your brand or easily accessible online.
Purposive (judgment) sampling
The researcher deliberately selects participants based on specific criteria. If you're studying how power users interact with advanced features, you'd intentionally recruit people who match that profile.
Best for: This method suits qualitative research where depth matters more than breadth, such as expert interviews, case studies, and niche research questions where random sampling would waste resources on irrelevant respondents.
Drawback: Entirely dependent on the researcher's judgment. If the selection criteria are wrong, the sample is wrong.
Snowball sampling
Start with a small group of participants and ask them to refer others who fit the criteria. The sample grows like a snowball rolling downhill.
Best for: This method works well with hard-to-reach populations, such as freelance workers, people with rare medical conditions, or niche professional communities—any group where no complete list exists and members are best at identifying each other.
Drawback: The sample tends to cluster around social networks. People refer people like themselves, which can create homogeneity that misses other segments of the population.
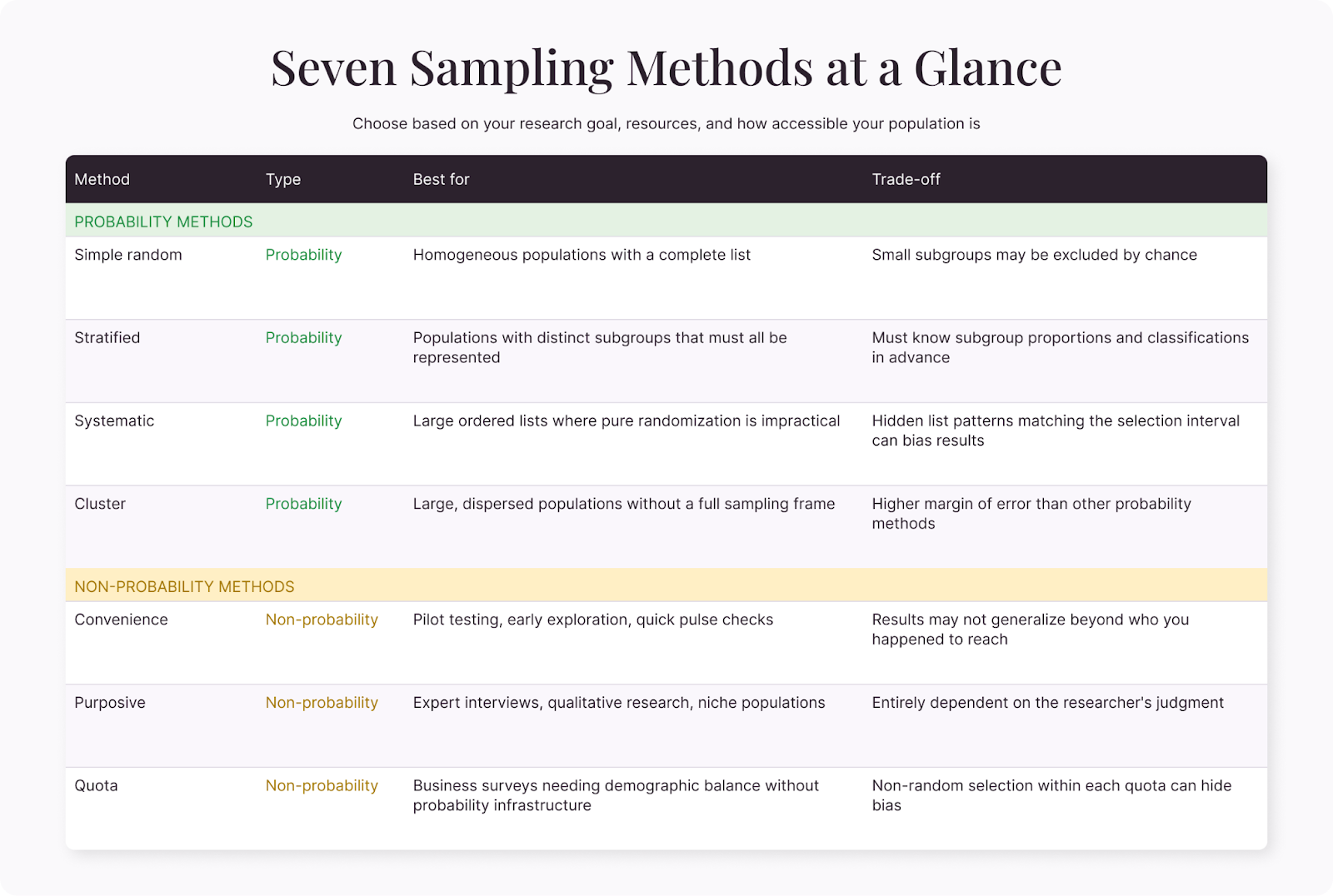
Quota sampling
Set demographic targets for your sample and recruit until each target is met. If you need 50% women and 50% men, you recruit from each group until you hit 50. Selection within each quota isn't random—you take whoever's available.
Best for: This method suits business surveys where you want demographic balance without the infrastructure for probability sampling. Market research panels often use quota sampling to ensure a diverse respondent pool.
Drawback: Non-random selection within quotas means hidden biases can persist. Two 35-year-old women might have very different perspectives, and the ones who happen to respond may not represent the others.
How to choose
Selecting a sampling method comes down to answering four questions:
What's your research goal? If you need statistically generalizable results (policy decisions, academic publication, regulatory compliance), you need a probability method. If you need directional insights for business decisions, non-probability may be sufficient.
What resources do you have? Probability sampling requires a sampling frame, more time, and often more budget. If you're working with limited resources and a tight timeline, non-probability methods get you usable data faster.
How accessible is your population? If you have a complete customer database, simple random or stratified sampling is straightforward. If your population is dispersed, unlisted, or hard to reach, cluster or snowball sampling may be your only option.
How important are subgroups? If comparing results across segments (regions, demographics, customer types) is central to your research, stratified sampling ensures each segment is adequately represented. If you just need an overall picture, simpler methods work.

Combining methods in practice
Real research rarely uses a single method in isolation. A few common combinations work well for business surveys:
Stratified random for your core sample, convenience for pilot testing. Use a quick convenience sample to test your survey instrument—check for confusing questions, broken logic, and unclear wording. Then switch to stratified random sampling for the actual data collection. The pilot gives you confidence in the tool. The probability sample gives you confidence in the data.
Quota sampling with demographic weighting. Start with quota sampling to ensure your major demographic groups are represented, then apply statistical weights to fine-tune the proportions. This hybrid approach is faster than pure probability sampling while producing results that are closer to representative than pure convenience.
Snowball sampling to identify the population, then probability sampling to study it. When you don't have a complete list of your target population—freelancers, early adopters of a niche product, members of an informal community—snowball sampling helps you build that list. Once you have enough contacts, switch to random sampling from the list to produce more generalizable results.
The key is knowing which method handles which job. Use non-probability methods where speed and access matter most. Use probability methods where generalizability matters most. And document your choices so anyone evaluating your results understands the trade-offs you made.
The honest takeaway
At the end of the day, no sampling method is perfect. Every one involves trade-offs between rigor, cost, speed, and practicality. The goal isn't to pick the "best" method in the abstract—it's to pick the one that gives you the most trustworthy answers given your constraints.
The last important takeaway? Be transparent about your method when you present results. "We surveyed 400 customers using stratified random sampling across three regions" is credible. "We surveyed some people" is not.
How you sampled is part of the story your data tells, and your audience deserves to know it.


.png)
